Mastering Efficient Data Cleanup in Vector Search Systems
Optimize vector search performance by effectively managing data cleanup.
TL;DR
- Traditional cleanup methods are inefficient and risky.
- Usage-based cleanup minimizes query failures and optimizes disk usage.
- Implementing usage tracking is key to effective cleanup.
- This article provides in-depth analysis and practical examples.
Understanding Traditional Cleanup Strategies
Vector search systems typically use data cleanup mechanisms to maintain performance and free up storage. Traditionally, these cleanup strategies have been time-based, which can be problematic.
| Feature | Traditional Cleanup | Usage-Based Cleanup |
|---|---|---|
| Query Failures | ❌ | ✅ |
| Disk Usage | ❌ | ✅ |
| Complexity | ✅ | ❌ |
| Data Loss | ✅ | ❌ |
The Pitfalls of Time-Based Deletion
Time-based deletion strategies can lead to data loss and query failures, as important files are deleted prematurely.
⚠️ Time-based deletion can result in critical data being removed before dependent tasks are completed.
Introducing Usage-Based Cleanup Strategies
A usage-based cleanup strategy ensures that files are retained until all dependent tasks are completed, preventing data loss and optimizing disk usage.
# This function checks if a file is in use, preventing premature deletion.
def is_file_in_use(file_id):
return any(task.uses_file(file_id) for task in active_tasks)Setting Up a Usage-Based Cleanup System
To implement a usage-based cleanup strategy, you need to carefully track the status of each file and associated tasks.
# Example initialization of file status tracking
file_status = {}
active_tasks = []Configuration and Management
Once the system is initialized, configure the cleanup process to check file status before deletion.
# Example configuration with inline comments
cleanup_config:
check_interval: 60 # Time in seconds between checks
file_deletion_policy: 'usage_based' # Deletion policy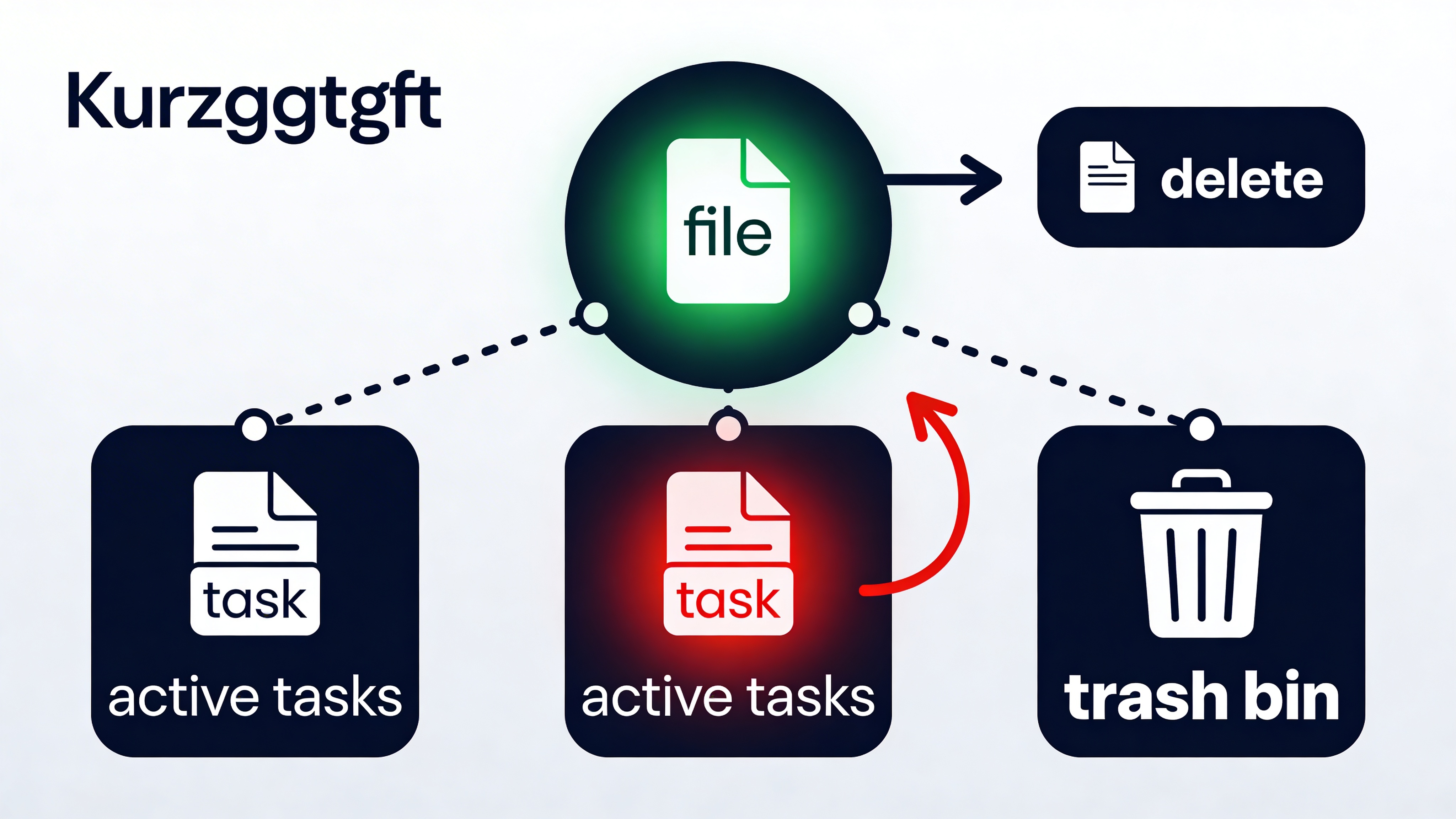
⚠️ Incorrect implementation of usage tracking can lead to file retention issues and data bloat.
Benefits of Implementing Usage-Based Cleanup
Preventing query failures and optimizing disk usage are key advantages of adopting a usage-based cleanup strategy.
- Minimizes query failures by ensuring file availability until tasks are complete.
- Optimizes disk usage by deleting files only when necessary.
- Enhances overall system performance by reducing file management overhead.
See Also
- Vector Search Optimization Techniques — https://example.com/vector-search-optimization
- Managing Large-Scale Data Insertion — https://example.com/large-scale-data
- Best Practices for File Management in Python — https://example.com/python-file-management
Ready to deploy your OpenClaw AI assistant?
Skip the complexity. Get your AI agent running in minutes with EasyClawd.
Deploy Your AI Agent